Map-Reduce paradigm is a different than traditional programming paradigm. In Map-Reduce processing is split in to two main phases called Map and Reduce. Apache typical example of
word_count, which counts how often words appear in a documents. This will requires one map-reduce job. Intuitively, This is not the case in other tasks, You might need more than one map-reduce job to accomplish your task. Before, giving an example, I will discuss the main idea of Map-reduce paradigm briefly to create a basic background. let's assume the word_count example.
Single Map-Reduce Job
We have a document that contains several words, our task is to count how often each word appear. Map-Reduce paradigm takes the file and distribute it over your cluster. Basically it splits the whole file into chunks. Each chunk by default 64KB. Each splits goes through there phases Map, Shuffle "Combine" , and Reduce phase. Figure (1) illustrate the word count job.
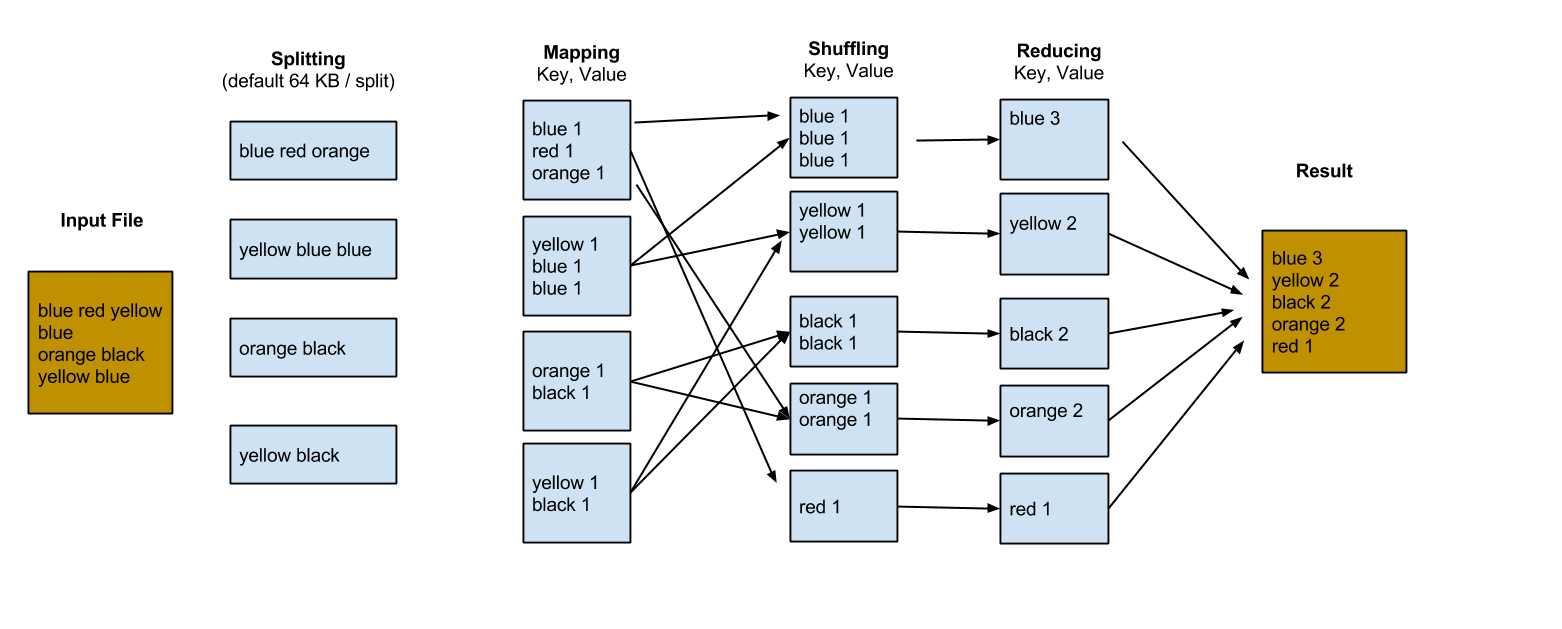 |
| Figure (1) word count map-reduce |
A brief description of each phase:
1- Split: In hadoop file system "HDFS" the default block size is 64KB you can change this from the configuration.
2- Mapper : The mapper process each split. Rather than consider the whole document. In mapper phase our input is a split. which is contains part of the document. In map phase we tokenize words in each line. As in HashMap structure <Key,Value> pair. We set each token "word" as the key, and assign it's value to 1.
3- Shuffler "combiner": Hadoop, sorts all similar keys together, to be passed to the reducer later.
4- Reducer: reducer process each sorted split. In words count example, reducer calculate the number of words based on the given value.
Multiple Map-Reduce Job
Now it is easy to discuss several Map-Reduce job in order to complete your task. What do we really mean by several Map-Reduce job, is that once a first Map-Red finish the output will be an input for the second Map-Red and the output of the second Map-Red will be the result.
Let's assume that we would like to extend the word count program. Let's assume that we would like to count all words in twitter dataset. So the first Map-Red will read twitter data and extract the tweets text. The second Map-Red is the wordcount Map-Red which analyze twitter and produce the statistics about it. " you can find the source code below "
InputFile -> Map-1 -> Reduce1 -> output1 -> Map2 - > Reduce-2 -> output2 -> ....Map-x
There are two several way to do this, I will present only one way of doing several Map-Red by define JobConf() for each Map-Red.
First create the JobConf object "job1" for the first job and set all the parameters with "input" as input directory and "temp" as output directory. Execute this job: JobClient.run(job1).
Immediately below it, create the JobConf object "job2" for the second job and set all the parameters with "temp" as input directory and "output" as output directory. Finally execute second job: JobClient.run(job2).
The source code to illustrate this example.
package MultipleJob;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import twitter.Twitter;
import twitter.TwitterMapper;
import twitter.TwitterReducer;
import wordCount.WordCount;
import wordCount.WordCountMapper;
import wordCount.WordCountReducer;
/**
*
* @author louai
*/
public class Main {
public static void main(String[] args) throws
IOException, InterruptedException, ClassNotFoundException{
System.out.println("*****\nStart Job-1");
int result;
JobConf conf1 = new JobConf();
Job job = new Job(conf1, "twitter");
//Set class by name
job.setJarByClass(Twitter.class);
job.setMapperClass(TwitterMapper.class);
job.setReducerClass(TwitterReducer.class);
//Set the output data format
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setNumReduceTasks(0);
Path input = args.length > 0
? new Path(args[0])
: new Path(System.getProperty("user.dir")+"/data/tweetsTest.txt");
String outputPath = System.getProperty("user.dir")+"/data/hdfsoutput/tweets";
Path output = args.length > 0
? new Path(args[1])
: new Path(outputPath);
FileSystem outfs = output.getFileSystem(conf1);
outfs.delete(output, true);
FileOutputFormat.setOutputPath(job, output);
FileInputFormat.setInputPaths(job, input);
//return job.waitForCompletion(true) ? 0 : 1;
result = job.waitForCompletion(true) ? 0 : 1;
System.out.println("*****\nStart Job-2");
JobConf conf2 = new JobConf();
Job job2 = new Job(conf2, "louai word count");
//set the class name
job2.setJarByClass(WordCount.class);
job2.setMapperClass(WordCountMapper.class);
job2.setReducerClass(WordCountReducer.class);
//set the output data type class
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(IntWritable.class);
Path input2 = args.length > 0
? new Path(args[0])
: new Path(outputPath);
Path output2 = args.length > 1
? new Path(args[1])
: new Path(System.getProperty("user.dir") + "/data/hdfsoutput/filter");
FileSystem outfs2 = output2.getFileSystem(conf2);
outfs.delete(output2, true);
//Set the hdfs
FileInputFormat.addInputPath(job2, input2);
FileOutputFormat.setOutputPath(job2, output2);
result = job2.waitForCompletion(true) ? 0 : 1;
System.out.print("result = "+result);
}
}